Paper link: https://arxiv.org/pdf/2505.09598
While doing some research on the environmental impact of LLMs, especially their energy consumption, I stumbled upon this interesting study that attempts to estimate the power consumption of various LLMs. There's a Power BI Dashboard showing off the study's findings in a more digestible manner.
However, looking at the linked dashboard, I quickly noticed that something felt off about the data. DeepSeek R1 and V3 were ranked way higher than I would've expected, so I set out to understand how this data was created in the first place. This post also serves as a cautionary tale about data found online, even from reputable sources.
The problems
Below is the equation used by the study to calculate the estimated power consumption of LLMs per query of fixed length (water consumption and carbon footprint are derived from this):
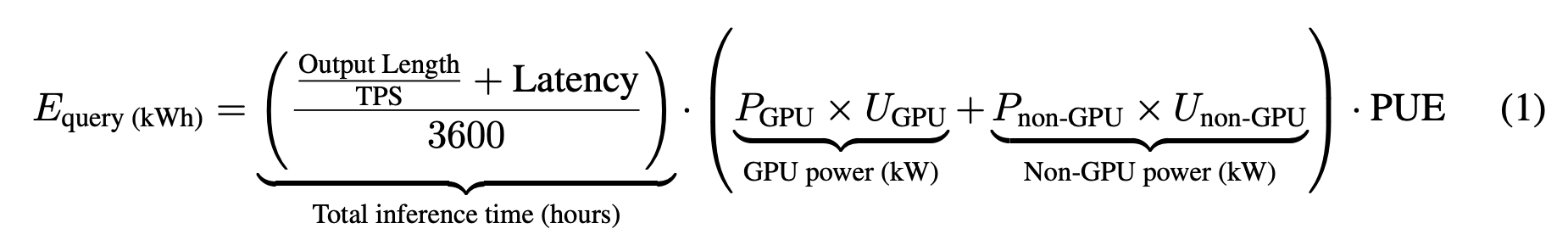
But there's a flawed assumption here. The first part of the equation calculates the inference time of a query, then multiplies it with the estimated power draw of the infrastructure running the LLM (which is estimated based on the LLMs size, which is estimated as well for closed models). PUE stands for Power Usage Effectiveness, which in this case accounts for additional datacenter overheads.
In this equation, as TPS (Tokens Per Second) increases and latency (Time To First Token) decreases, the energy consumption per query goes down. It's important to note that they didn't run the models in some kind of controlled lab setup, but just measured against the public APIs. Also, note that the infrastructure to run the models is assumed to be the same for all models in a model class (which is based on the actual or estimated size of the model, with all models that can be considered somewhat state-of-the-art (SOTA) in the "Large" class).
To put it into perspective, this approach is a little like putting all cars with 200+ horsepower into the same category, assuming a static fuel consumption per hour and then letting them drive 200km to see which one gets there the fastest, which must mean it's the most efficient.
Even if we assume the hardware estimates to be correct, there is still a problem with regard to capacity. DeepSeek (the company) simply doesn't have access to anywhere close the amount of GPUs OpenAI or Anthropic are using, but still have to serve a large amount of users. Let's assume the worst case: at the time a new query arrives, there is simply no capacity for it. What happens now is that the query simply has to wait for others to finish before it gets scheduled for completion. The cost of keeping it in memory while waiting is completely negligible, but the above equation would still assume it to draw full power.
At the other end, techniques like speculative decoding can increase compute utilization to increase TPS, which means more power consumption for more speed. Then there's also the option of simply using more than the assumed 8 GPUs per model instance, which is almost certainly something that's happening and would result in faster responses while drawing more power.
Could they have done better?
However, all of these flaws are simply caused by the fact that due to the complexity of on-scale LLM-inference and almost all providers not being transparent about how they actually do it, there is a lot of guesswork in trying to figure out the actual environmental costs of running these models.
This paper should to be seen as an attempt to put some data into our hands, even if it is based on many potentially flawed assumptions and rough estimates. I think the authors could have done a better job of acknowledging these flaws, but they're not at fault for their existence. They were simply working with what they had.
Unless model providers start releasing their own data, I think this paper might be the best we can do for now.
Can we still learn from this?
I think there are still some things we can take away from this data. I think it's safe to say that we can disregard the absolute values, but we can still, albeit carefully, use it as a relative benchmark between models. The DeepSeek models ranked so far up are the ones hosted by DeepSeek themselves on weaker GPUs due to US export controls, but the authors also included the DeepSeek models hosted by Azure in their data, which perform a lot better on infrastructure that's likely to be more comparable to OpenAI and others.
Therefore, looking at the top models of each company, we can come up with this ranking as of today (from most efficient to least efficient):
1. Google (running on their own TPUs, so careful with this one)
2. DeepSeek
3. Anthropic
4. Mistral
5. OpenAI
6. xAI
I often see findings from AI papers with questionable methodology or data representation taken at face value, without examining how those claims were actually produced. One well-known example is the “Model Collapse” paper. I hope this analysis encourages readers to approach such claims more critically in the future.